 供需大廳
供需大廳
 登錄/注冊
登錄/注冊 供應商登錄
供應商登錄










榮格工業資源APP
了解工業圈,從榮格工業資源APP開始。
歡迎來到榮格工業資源網!

供需大廳

登錄/注冊
公眾號

更多資訊,關注微信公眾號
小秘書

更多資訊,關注榮格小秘書
郵箱
您可以聯系我們 info@ringiertrade.com

電話
您可以撥打熱線
+86-21 6289-5533 x 269
建議或意見
+86-20 2885 5256
頂部

榮格工業資源APP
了解工業圈,從榮格工業資源APP開始。



臺積電在其2025年的技術研討會上揭曉的“明日CoWoS”的技術,讓3D堆疊能力再上一個臺階。首次亮相的“集成電壓調節器”(IVR)可嵌入芯片內,靠近處理器以提升電源調節效率。這一技術革新,憑借臺積電在CoWoS技術上的壟斷優勢,可能使臺達電、英飛凌等電源模塊供應商的獨立產品因融入CoWoS而消失。
臺積電的技術變革,把整個產業推向一個高度,即高算力和低功耗的雙追求達到一個高度。本文將從歷史到現在,背后全面梳理半導體技術創新。
算力與功耗的糾纏史
在芯片的發展史中,我們只看見摩爾定律推動算力發展。實則,芯片不斷提高算力時,功耗一直是工程師們頭疼的事情。高算力和低能耗,一直是半導體從業人員的追求。
簡稱,吃最少的飯,干最多的活兒。金牌牛馬實錘了。
就拿整個電子產業最初期的祖師爺——電子管來說,這個被稱作電子產業“初代神器”的玩意,一度成為20世紀前半葉的電子頂流。它從最初的 “整流/檢波” 功能,到實現 “信號放大”,再到支撐早期計算機、雷達、通信設備的規模化應用。能力值被拉滿,卻因算力和功耗極限,被晶體管一瞬間取代。
畢竟啟動電子管的陰極需要通過電流加熱才能發射電子,單個電子管功耗可達幾瓦至幾十瓦,大量使用時總功耗極高。
這種電能饕餮必將成為歷史。
后面便是晶體管時代,相較于電子管,晶體管的PN結無需 “加熱陰極” 就能控制電流,從原理上規避了電子管的功耗、發熱缺陷。而在接下來的幾十年晶體管自我革命里,晶體管們削尖了頭往芯片里鉆。顯然,在追隨摩爾定律這條路上,產品的核心訴求就是讓越小的黑方塊里放下越大的算力,同時不要發燙。
在工藝制程不斷演進進程中,大致經歷了PMOS(P溝道金屬氧化物半導體)→NMOS(N溝道金屬氧化物半導體)→HMOS(高性能金屬氧化物半導體)→CMOS的過渡,以及FinFET(鰭式場效應晶體管)、GAA(環繞柵極晶體管)等新型結構的引入,不斷突破物理極限,提升晶體管性能并降低功耗。
下面就用一小段說清一個工藝,來給大家快速回看這段歷史影像。
首先登場的是PMOS,PMOS的杰出代表就是1971年英特爾推出的4004芯片,這是其第一款商用4位微處理器,采用10μm PMOS工藝,特點就是采用P型硅作為襯底,鋁作為互連金屬,二氧化硅作為絕緣層。PMOS晶體管的空穴遷移率較低,導致工作頻率僅 108KHz,功耗較高(15V 工作電壓)。后續的8008芯片也是沿用PMOS工藝,工藝未變,但從4位處理器升級到了8位,指令集擴展至 48 條,晶體管數量增至 3500 個。使得整體性能翻倍。

圖:英特爾推出的4004芯片
NMOS登場也非常快,僅僅發生在4004芯片的三年后。在1974年推出的8080采用6 微米NMOS工藝,以電子遷移率更高的N 型硅取代 P 型硅,使晶體管開關速度提升10倍,工作頻率躍升至 2MHz。集成度也大幅提高,晶體管數量增至6000個,支持 64KB 內存尋址,處理速度達 0.64MIPS,成為首款被廣泛應用于微型計算機的處理器。
再過四年,HMOS來臨。采用3微米 HMOS工藝的8086芯片,是 x86 架構的奠基之作。
該工藝的特點就是在 NMOS 基礎上優化硅柵結構,通過離子注入精確控制摻雜濃度,晶體管密度提升近 5 倍,集成2.9萬個晶體管。HMOS工藝的功耗降低至5V,且與TTL邏輯電路兼容。
隨后CMOS開始嶄露頭角,這個上世紀60年代被提出的工藝技術,直到80年代中期發揮自己一個突出優勢——低功耗。如1985年英特爾 80386SX采用1.5μm CMOS,主頻達 20MHz,功耗僅為同性能 HMOS的1/5。CMOS 最終取代HMOS,本質是半導體需求從 “速度優先” 轉向 “速度與功耗平衡” 的必然結果。
而在65nm工藝節點時,功耗問題又突出出來。時間發生在2004年,產業界發現晶體管密度的改善在降低晶體管功耗和提高晶體管開關速度方面變慢。2005 年ITRS(國際半導體技術路線圖)公布的研究表明,在 65nm 節點上,動態功耗密度和泄漏功耗將分別增加 1.43 倍和 2.5 倍。到 2007 年左右,業界已經明顯意識到 65nm 工藝下漏電流及功耗急速上升的問題,并開始引起警覺。
解決65nm功耗問題,產業采用的是組合拳。材料(High-k/金屬柵)、結構(應變硅/STI)、設計(Multi-Vth/電源門控)、封裝(倒裝芯片/散熱)等技術協同。這些技術在 65nm 時代完成研發和驗證,在45nm節點全面商用,不僅緩解了65nm的功耗危機,更奠定了后續納米級工藝(32nm、22nm等)的發展基礎,使摩爾定律得以延續至 21 世紀第二個十年。
此后,當集成電路芯片制造產業的特征尺寸縮小到22nm時,傳統的CMOS平面微納加工工藝技術面臨性能劣化等問題。2011年,英特爾公司在其 22nm 工藝技術節點上首次推出商品化的Fin-FET(鰭式場效應晶體管)產品Ivy - Bridge,大大增加了晶體管的柵控能力,降低了芯片功耗。此后,臺積電等公司在 Fin - FET 技術節點上不斷發展,工藝尺寸達到14nm、7nm、5nm等。此外,為了進一步提高集成度,3D 集成技術如硅通孔(TSV)技術也得到了發展。

FinFET與GAA結構示意圖
近幾年,GAA(Gate-All-Around,全環繞柵極)結構橫空出世,是繼 FinFET之后的新一代半導體器件架構,通過柵極完全環繞導電溝道實現更精準的電流控制,是支撐 3nm 及以下先進制程的核心技術。
在不斷追求高性能芯片的道路上,高溫和漏電成為摩爾定律失效的主要劊子手。大家從各個角度來尋求大算力的突破。
此時,產業界誕生一個新詞——超越摩爾(More than Moore)。
超越摩爾時代的大廠策略
超越摩爾告訴你什么叫條條道路通羅馬。
既然大家的目的都是追求大算力突破,追求性能和功耗的平衡,那晶體管微縮這條路并不是唯一解,奈何這招還失靈。這些通羅馬的道路上,先進封裝異軍突起,既然單一芯片無法滿足要求,那就讓所需要芯片的裸Die封裝到一起。其中3D IC通過“垂直堆疊+高密度互連”重構芯片形態,解決了傳統 2D IC在“性能、功耗、面積”上的瓶頸。比如手機 SoC 可將邏輯芯片、LPDDR 內存、NAND 閃存垂直堆疊,體積縮小40%以上。
這一部分,給大家羅列一下,全球頂尖企業是如何超越摩爾的。
首先是臺積電,作為全球工藝制程走在最前沿的晶圓廠,臺積電一邊繼續推動先進工藝的發展,一邊磨礪先進封裝技術,其中于2011年推出第一代CoWoS(Chip-on-Wafer-on-Substrate)技術。
CoWoS是由CoW和oS 組合而來,先將芯片通過Chip on Wafer(CoW)的封裝制程連接至硅晶圓再把CoW 芯片與基板連接,整合成 CoWoS。核心是將不同的芯片堆疊在同一片硅中介層實現多顆芯片互聯。
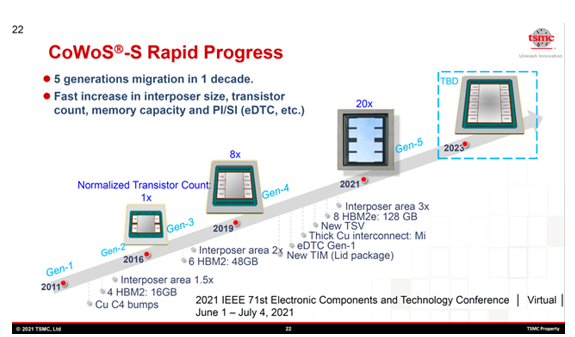
臺積電CoWoS路線圖,圖源:臺積電官網
CoWoS 技術經歷了多個重要發展階段。2011 年的第一代,2014 年發展至第二代,2016年推出第三代技術,2019年第四代實現2X光罩尺寸中介層突破,這個巨大的中介層裝有一個大型邏輯芯片和6個HBM2。由于一個HBM2存儲的容量增加到8GB(64Gbit),所以總容量為48GB(384Gbit),是第三代容量的3倍。2021 年推出第五代技術,支持 3.3X光罩尺寸(約 2700mm²)。技術演進的核心驅動力是 AI 芯片對高帶寬內存集成的需求,特別是 HBM(高帶寬內存)的堆疊需求。
2024 年,臺積電推出了革命性的封裝技術升級,采用 120mm×150mm 超大基板,實現 7,885mm² 的 9.5 倍光罩面積封裝,同時通過新型熱界面材料解決超高功耗散熱難題。這一技術躍進標志著 CoWoS 進入“巨芯片”時代,為 AI 算力的進一步提升提供了物理基礎。
英特爾的先進封裝則叫EMIB(嵌入式多芯片互連橋接)與Foveros 。其中,EMIB為 2.D封裝,摒棄傳統大尺寸硅中介層,采用局部硅橋嵌入式設計:在有機基板的芯片間隙處嵌入小型硅橋,通過硅橋上的高密度銅線實現相鄰芯片的高速信號傳輸。硅橋與芯片間通過微凸塊鍵合,基板則承擔電源分配與散熱功能。

英特爾封裝路線圖,從傳統封裝到先進封裝(圖源:英特爾官網)
Foveros則為3D封裝,其核心架構采用“基礎晶圓+堆疊芯粒”設計,即基礎晶圓(通常為14nm I/O芯片)提供電源管理與外部接口,頂部堆疊邏輯芯粒(如 CPU、GPU),通過微凸塊或混合鍵合實現垂直互連。
三星則是以存儲為核心,構建 “垂直堆疊 + 混合集成”的3D封裝技術體系。其中,3D V-NAND 堆疊技術通過電荷俘獲層實現超多層堆疊;HBM-PIM 封裝則是將高帶寬內存(HBM)與處理芯粒通過混合鍵合集成,實現內存內計算;X-Cube 3D IC采用硅通孔(TSV)+ 微凸塊鍵合架構,支持 8 層邏輯芯粒堆疊。
國內的封裝大廠如長電科技,采用XDFOI與3D SiP協同發展策略,前者是采用扇出型架構替代傳統硅中介層,支持大尺寸封裝;后者系統級封裝則是高性能領域的高密度 3D SiP 支持6層芯粒堆疊。通富微電Chiplet 為核心的 3D 封裝技術體系,形成兩大核心平臺,分別為VISionS 先進封裝平臺與3DMatrix 技術平臺,前者融合 2.5D/3D 集成與 MCM-Chiplet 技術,采用扇出型架構與TSV硅通孔結合方案;后者集成 TSV、eSiFo(扇出封裝)與3D SiP 三大核心技術,通過硅通孔實現垂直互連。
誠然,芯片的發展是整個產業鏈玩家共同推動,上面所提及的所有技術和案例都是典型企業的做法,背后是設計公司、EDA/IP公司、封測廠、晶圓廠、設備材料、軟件公司等共同推動的生態,缺一不可。
生態的重要性
本期話題是高算力+低功耗。一高一低的平衡中,我們再拔高一個視野,看一看應用端的視角。回歸芯片本質,其作用就是推動實際應用發展,而終端應用就是一個生態。
2025年我們看見一個非常有意思的大模型產品——DeepSeek。DeepSeek 攻克了大模型訓練的 “不可能三角”,其V3模型僅用557.6萬美元便實現了與GPT-4 Turbo相當的性能,通過動態調整神經元激活范圍,將算力消耗降低至行業平均水平的1/10,打破了傳統大模型依賴海量數據與算力的研發路徑。
也就是說,在芯片算力往上爬得費勁的時候,軟件產品努力把所求降低,從而達到完美適配。
同時,DeepSeek也是全球首個全開源多模態模型體系,公開了模型權重、訓練代碼、數據清洗流程和微調工具等,大家可以自行下載與部署模型,降低了 AI 技術的開發門檻,吸引了全球開發者參與。
另一個值得一提的就是英偉達的CUDA生態,CUDA 是英偉達的并行計算平臺和編程模型,2006年推出,英偉達的CUDA策略也能夠從宏觀角度來降低功耗拔高能力上線。自身的GPU硬件與CUDA緊密耦合,比如NVLink 高速互聯技術和Tensor Core等硬件特性通CUDA能得到充分利用。
縱觀整個芯片發展,算力和功耗是永恒的話題,哪怕是逼近物理極限,也要再進一步。瘋狂的技術大拿們,為了讓電子世界更加科幻,也在日夜創造奇跡。


